记录一次保持业务规则一致性的小优化
Table of Contents
前提 #
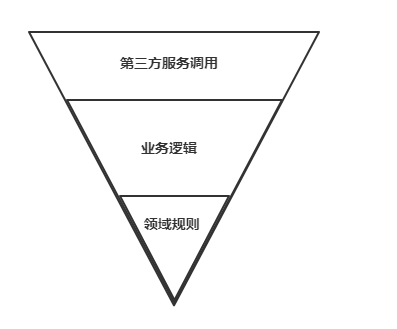
有些服务的逻辑非常复杂,这导致了其逻辑层中的代码非常混乱。
为了让逻辑层中的代码更加清晰,我们抽象出了一个规则层来存放领域规则的代码。
场景 #
举一个场景:同步企业微信和飞书的组织部门和人员。
规则层的责任 #
规则层中抽离了逻辑层中底层的领域规则,如:
- 同步企微员工到飞书的规则
- 同步企微部门到飞书的规则
遇到的问题 #
同步的方式有两种:
- 全量同步:获取两个数据源全量数据,进行比对、映射,然后在目的数据源进行部门、员工的新增、删除、更新等操作
- 事件同步:监听来源数据源的变更事件,然后在目的数据源进行对应的操作(如部门或者员工的新增、删除、更新)
尽管有不同的同步方式,但是我们的领域规则应该只有一份。这导致了一些问题,以同步一个员工举例。
同步一个员工大致需要三步:
- 获取员工信息(从来源数据源获取信息)
- 同步员工所在部门(部门在目的数据源可能不存在,因此需要先同步部门)
- 创建/更新员工(同步到目的数据源)
同步员工需要获取员工和部门信息,在两种同步方式中获取数据的方式不同:
- 在全量同步中,已经拉取了双方的信息,这时候获取员工和部门信息就是从内存中获取
- 在事件同步中,需要通过接口调用来获取员工和部门的信息
由于数据来源不同,所以在旧版本中,同步员工的业务规则有两套代码,那么我们在做功能变更的时候,就要同时修改这两套代码。
解决问题 #
一个领域规则应该只有一套代码,如何解决这个问题呢?
引入一个中间件,我把它命名为DataPool,本质上就是一个使用内存作存储的缓存池.
DataPool的使用方式是这样的:
- 在一次同步中,所有获取到的员工和部门数据都放到数据池。
- 业务规则代码在获取数据时,统一从
DataPool中获取,如果DataPool中存在数据则直接返回,否则调用对应的接口来获取数据,并存储在DataPool中。
通过调用DataPool,解决了由于数据源不一致导致的需要两套代码这个问题!
总结 #
DataPool的设计是非常简单的,但是却让代码更加立体,业务领域的规则更加聚合。
以前我的代码就是根据业务逻辑平铺出来,分不出主次。现在通过端口-适配器模式实现逻辑层与第三方服务的依赖倒置,通过抽象出规则层来聚合领域规则,使得项目代码的质量得到了明显的提升。