事件驱动系列—宽窄表分离
Table of Contents
案例背景 #
因为我们做的是HR的saas平台,所以我们有员工表、部门表等等。
奇怪的是,员工表有非常多的冗余字段,比如部门名称、部门负责人、岗位名称等等。这些冗余字段存在的原因是为了方便员工信息的展示——想一想,在员工详情页面去展示部门名称、岗位名称、上级名称等等诸多字段,如果不做冗余字段就需要关联大量的表,这样的查询效率是非常低的。
问题是这样违反了数据库范式的设计原则,在系统维护上也会带来很多问题:
- 更新部门、岗位等信息时,需要更新员工表中的冗余字段, 这造成员工领域难以维护——毕竟还得看部门、岗位等领域的脸色;
- 有的部门下有非常多的员工,也就是说,当一个部门的信息更新时,需要更新员工表里非常多的数据, 这无疑对员工表造成了很大压力;
- 冗余带来的一大问题就是数据的一致性——即员工身上的部门信息可能与部门表中的不一致:
- 员工表冗余的字段实在太多,事实上已经形成了一个非常”宽“的表,在这张表上做”增删改查“的效率非常低。
由于这些问题的存在,员工表,或者说整个人事系统,不仅性能很差,而且已经成为了一个非常难以维护的系统。
正确的设计 #
上述的问题都是由于员工表的冗余字段导致的,既然冗余字段会造成如此多的问题,那么如何在不冗余这些表的同时提高员工详情的查询效率呢?
我们可以使用宽窄表分离的方式来解决这个问题。
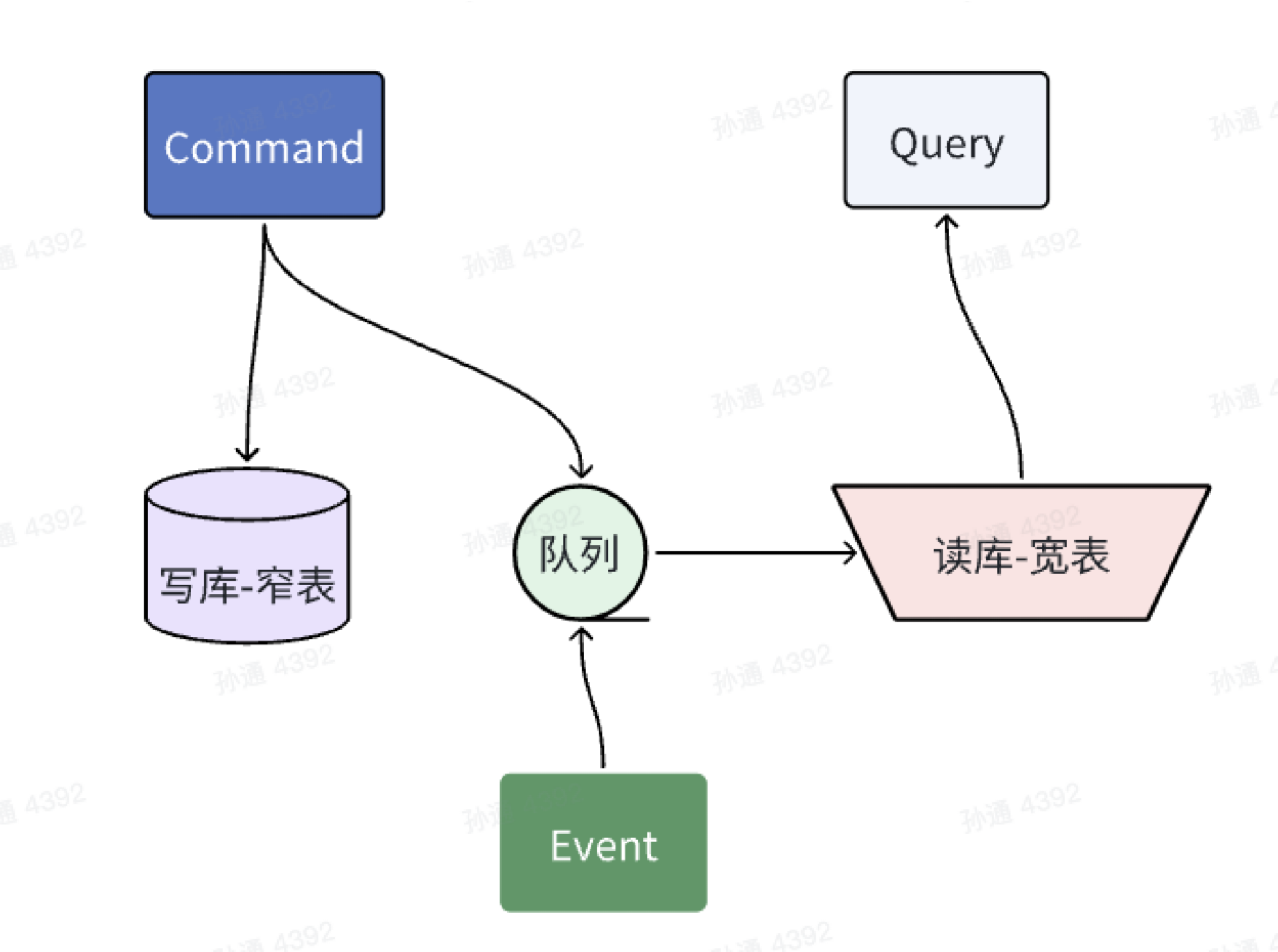
- 员工表只存必要的信息(我们称它为窄表),其他信息如部门名称、岗位名称不存储。这解决了员工表”增删改查“性能差的问题。即问题4.
- 单独创建一张读表用于冗余员工的详情信息(我们称它为宽表),这张表只用来查询用户信息,字段的更新都是通过事件通知的方式来完成。这解决了员工详情查询的问题。
- 通过消息中间件来接收部门、岗位等领域的更新事件来更新宽表的数据,这减轻了一次性更新大量员工表数据的问题,即问题2.
- 消息中间件的最少一次投递的特性还能保证数据的一致性,即问题3.
- 通过事件的方式对员工领域和部门等领域进行了解耦,即问题1.
这种拆分宽窄表的设计在业内往往称为”读写分离“.
对于读表的技术选型,可以使用和窄表一样的Mysql,也可以使用其他查询性能更高的存储方式,如Elasticsearch.
问题延伸 #
在实际场景中,人事系统只是整个HR系统的一部分,还存在其他系统,如:考勤系统、薪酬系统、培训系统、绩效系统等等。
这些系统虽然都是使用的Mysql, 但是其数据库实例是分开的,这意味着其他系统不能通过关联表的方式来获取员工的信息,当然这种设计也不规范——业务系统只能读取领域内的数据库表。
一种常规方式是通过接口来获取员工的信息,但是有些特殊情况是没办法这样做的,比如说:考勤系统需要按照员工名称来过滤考勤信息(我们当然可以先根据名称来获取员工列表,然后再根据员工列表来获取考勤信息,但是假设获取的员工列表长度为10000,那么将这10000个员工ID拼接成sql再去查询显然是很蠢的行为).
这时候就需要同步员工表的数据到其他业务系统。常用的工具是canal或Flink CDC.
我不认为这是一种优雅的方案,因为这种方案会导致系统间的耦合性非常高,一旦员工表的字段发生变化,就会影响到其他业务系统的表,这是非常危险的。
而在实际的场景中,由于员工表的冗余字段非常多,我们需要对其进行优化,而其他系统对员工表的”耦合“又导致我们在优化时束手束脚。
所以我认为一种优雅的方案是通过消息队列,以一种事件的方式来做员工信息的通知和消费:
- 员工领域维护好新增、更新、删除事件。事件的数据结构以领域逻辑为准
- 其他依赖员工表的系统自己订阅、消费这些事件,并存储在自己的数据库中
这样我们只需要保证员工信息事件的结构的完整,而不再与数据库强耦合。一旦我们需要更改数据库的字段,只要保证事件的数据结构完整即可。