短链与编码
Table of Contents
序言 #
现在的知识载体大多都以博客、公众号、视频为主,而这些载体则以”网址“的形式进行展现、链接。网络链接已成为我们的知识图谱的核心内容。
比如我复制了一个公众号文章的链接,这个链接如下:
https://mp.weixin.qq.com/s?__biz=MzAxOTc0NzExNg==&mid=2665541445&idx=1&sn=3b4a468f925464d8621af0c34cdf8b13&chksm=80d61706b7a19e10d6b88baf656d841c30c567291492f7b3dd77c0dfc0814d9c7e0f84350679&xtrack=1&scene=90&subscene=93&sessionid=1692600551&flutter_pos=6&clicktime=1692600558&enterid=1692600558&finder_biz_enter_id=4&ascene=56&fasttmpl_type=0&fasttmpl_fullversion=6817439-zh_CN-zip&fasttmpl_flag=0&realreporttime=1692600558127&devicetype=android-33&version=28002854&nettype=ctnet&abtest_cookie=AAACAA%3D%3D&lang=zh_CN&session_us=gh_463af1d02f3b&countrycode=CN&exportkey=n_ChQIAhIQZiLprP%2FkpW35Zi8OFWwQNRLrAQIE97dBBAEAAAAAAMvhKKINSNoAAAAOpnltbLcz9gKNyK89dVj0%2FUMkgu5qnig5JO4N2fG9%2FpOlEopRJ35ZBM0WMi6Dc7Bk4AKoY2gswCUO9%2BYW9c2CF5nuh49GdpyOicJHoibVO7Ss%2FLh4GuRP9v9HvMksSu7lC92SAiGc%2BnalOVnzvxQAKL0kAASOBDP48irkuxyR5KyJc4AT9RXgOYOAz2n16KrJ%2FF%2FdZyAirbUDtuGtUlYduDC3z5dIHs%2Fl1P7Oxp9CTGafsEgoHbFJDfSPt6SPDe%2BoUoj2FZpNpMwFkvravMLzMSnUmn8%3D&pass_ticket=91w%2FzhSf%2ByjBNDOCbp%2FnI8%2FTIw64HXq7EbPlGvcfaKkSiGseLG47ox7cq9LvV1H1&wx_header=3
如果在笔记中记录这样长的链接会非常影响人的心情。
将长链接变短也就有了它的应用场景。
使用短链的基本逻辑如下图:

构造短链 #
方法1:哈希+哈希碰撞检测 #
将长内容变短的一个常用方式是哈希,以上述公众号链接为例,常用哈希算法后的结果为:
| 算法 | 输出长度(位) | 输出长度(字节) | 结果 |
|---|---|---|---|
| CRC32 | 32bits | 4bytes | fc5e1ffe |
| MD5 | 128bits | 16 bytes | 17072f669395b4c9a312a179e584b787 |
| SHA-1 | 160bits | 20bytes | ce733e17b7b68be57db04319c1fc5dcbd65b0c93 |
| RipeMD-160 | 160bits | 20 bytes | 819b73db8f5322f24fe79304743fea77543d8470 |
| SHA-256 | 256bits | 32bytes | b95d720d5011b9540f303eb2a5f4126be23a6a2bce9d1a0083d58549db8c4f40 |
| SHA-512 | 512bits | 64bytes | 30c805a1f98b1d65c2c96c1c24008df966a918bb4633b2bae6eca7262cfe8be3ecfc2864096d85d1f3cab4f81065d6c66c8a157862f5063696ccbc2dc7c1575f |
我们希望短链尽可能的短,而哈希结果长度越短则哈希碰撞的概率越高。
假如我们采用CRC32作为短链的哈希算法,那么当链接数量超过8589934591(2^33-1)后就一定会有哈希碰撞的链接地址。对于这样的场景,我们需要增加哈希碰撞检测。整体流程如下:
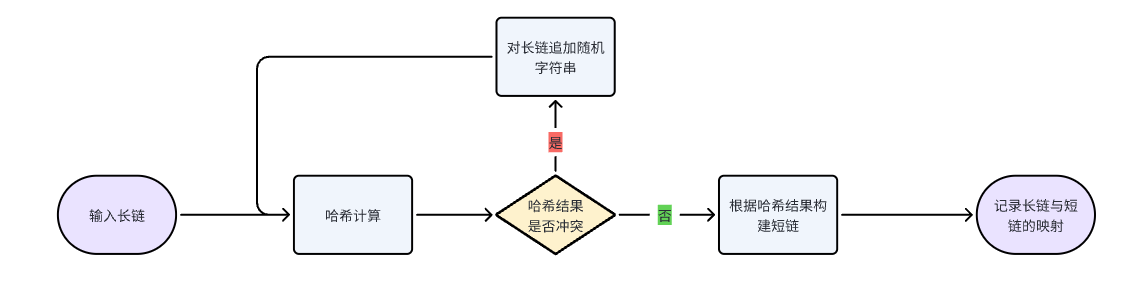
缺点 #
- 需要检测哈希碰撞,如果数据库中的链接数量非常大,这个过程会非常影响性能。
- 能够存储的链接数量有上限。如果使用CRC32作为哈希算法, 则最多存储
2^33-1个链接地址。
方法2:自增+编码 #
另一种常用的方式是将长链直接存储在mysql中,主键设置为自增。当插入数据后,数据库会返回主键。
这种方法的缺点在于将整数拼接在地址上既长又不美观,因此可以将其进行编码(以858193459为例):
| 编码长度 | 内容 | 编码结果 |
|---|---|---|
| 16 | 0~f | 3326fe33 |
| 0~9 、 a~z 、 A~Z | W4TjZ | |
| 64 | 0~9 、 a~z 、 A~Z 、 + 、 / | gZ8jcw== |
经base64编码后的长度不应该要比base62编码后的长。而这个结果是因为base64要保证编码结果的长度是4的整数倍,原本的结果应该是
gZ8jcw,于是要补充两个等号来得到4的整数倍。base64为什么要保证编码结果是4的整数倍?
- 一个base64字符正好可以由6个比特表示
- 一个字节需要8个比特
- 6和8的最小公倍数是24
- 3个字节的数据可以表示为4个base64字符(
3*8=4*6)- 也就是说在编码过程中,数据的最小单位是3个字节,编码结果的最小单位是4个字符
- 长度不足时用等号填充,解码时忽略等号
对于base16和base64,python都能够通过内置的函数来实现,base62则需要自己实现:
def base62_encode(num):
chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
base = len(chars)
res = ""
while num:
num, i = divmod(num, base)
res = chars[i] + res
return res or "0"

如果chars使用上述实现,那么base62之后编码很容易就能够被”预测“到(因为生成短链的值每次都加1)。为了避免这一点,可以将这62个字符的顺序打乱。
这种方式还有一个缺点,那就是依赖”自增组件“,目前比较流行的方式是使用mysql自增主键或者redis的incr命令,但这两者都容易形成单点故障或者性能瓶颈。为了避免这一点,需要做成分布式的服务,这时就需要设计一些”预获取“流程。
编码 #
上边我们使用base62将长链进行了短化处理。这其实就是一个编码的过程。
而编码实际上就是将现实抽象化的过程。

编码非常重要,它涵盖了生活中的方方面面:
- 我们看到的一切都是经过编码的。我们看到树叶是绿色的,是因为树叶没有吸收绿光,以至于它反射出来的光被我们的视网膜接收到,然后我们将这种信息编码为绿色。
- 不仅仅只有看到,闻到的,听到的,感受到的,这些都是经过编码的。
编码如此重要,以至于编码能力决定了我们解决问题的能力。
Geohash #
如何让消费者找到地理位置上距离相近的商家?地理位置需要纬度和经度两个维度,当数据量很大时即使加索引也需要遍历很多数据。那有没有办法将两个维度合并成一个维度呢?
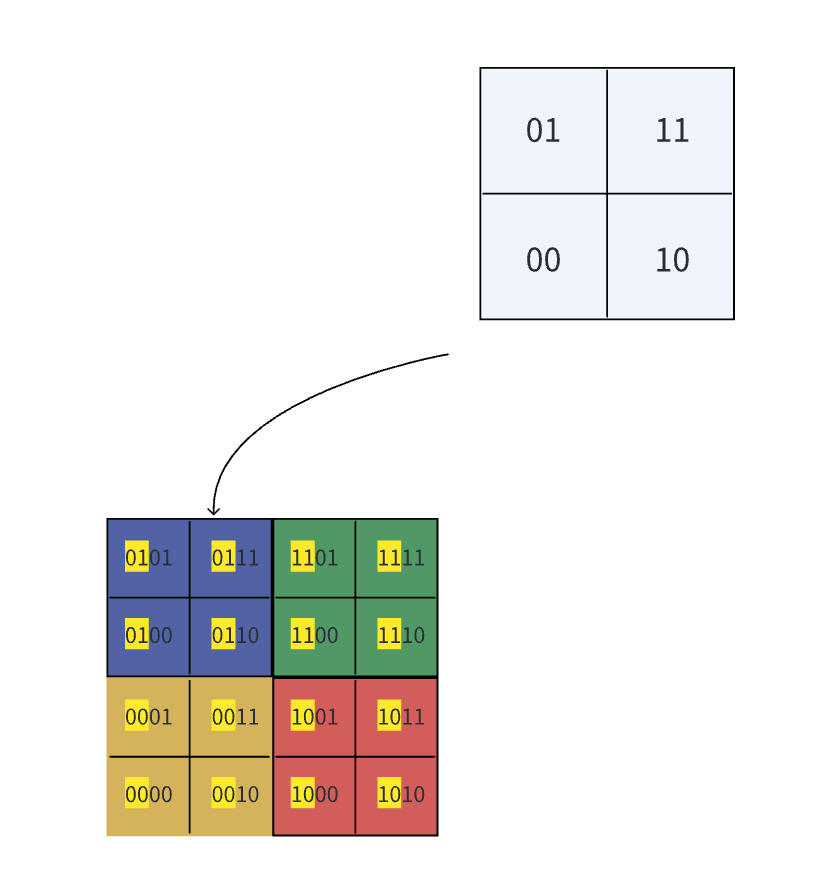
将地图分成四份,这四份可以用两个比特来表示,然后再将每份分成四份,递归这个过程,直到最小的不可分长度。于是谷歌公司的地理位置就可以用1001 10110 01001 10000 11011 11010来表示,base32之后则是9q9hyu。这样我们将可以用一个维度来标识商家的地理位置。
打破固定思维 #
提升编码能力需要打破传统的固定思维视角,需要赋予新的计算机意义。
看到64这个数字,一般人只会将其视为两个十进制数字,而在计算机的世界里,理解为6个二进制可能会得到不一样的结果。
假设有64瓶药,其中一瓶是假药,假设小白鼠吃到假药必死,吃到其他药不会死,而药效发作需要三天。现在我们只剩下最后三天,那么找到那瓶假药最少需要多少只小白鼠?
最简单的办法当然是用64个小白鼠分别尝试一瓶药,但这不是最好的办法。
如果我们把64看作6个二进制,那么只需要6只小白鼠就能找到那瓶假药。
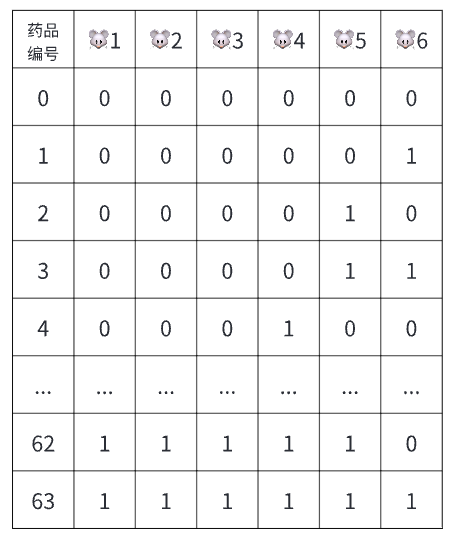
让每只小白鼠分别吃下表格中对应为1的药品,那么三天后,假设🐭4、🐭5、🐭6仍活着,其他三只死掉了,那么说明编号为111000的药品是毒药,翻译成10进制就是56,因为只有这瓶毒药是🐭1、🐭2、🐭3都吃的,🐭4、🐭5、🐭6都没吃的。