异地多活
Table of Contents
背景 #
随着用户的日益增多,系统的质量问题越来越突出。
想象一下:用户正在使用软件,突然软件崩溃了、不能用了,这时候用户肯定要理(ma)解(niang)的。如果一年只崩溃一两次还好(当然,如飞机、火车运行所需要的软件是绝对不能出问题的),如果每隔几天就来这么一下,那么用户可能就要寻找替代品了。2B的产品更是如此(业内通常使用SLA来描述可靠性,也就是大佬们常说的4个9、5个9)。
提升服务质量的手段有很多,如:
-
良好的代码风格、积极的code review、完善的自动化测试——在根上减少问题出现的可能性
-
合理的监控、报警、预警——保证第一时间内得到通知甚至提前预知风险
-
科学的熔断策略——减小一个低质量的服务造成全体系统崩溃的风险
-
完善的链路追踪、日志系统——提高解决问题的速度
-
善用灰度网关——减少重构系统带来的风险以及损失
-
。。。
尽管目前的手段众多,但是如果一个地区发生了“黑天鹅”事件,如没有预警的停电、地震、海啸,又碰巧这就是我们的服务器所在地,那么上述手段也是无能为力。
所以我们就需要更强大的容灾方案——异地多活。
目标 #
实现两地三中心方案。
什么是两地三中心?就是在两个区域部署三套服务——一个区域一套,另外一个区域两套。大部分两地三中心是在同城双活的基础上,增加了异地灾备数据中心。而对我们来说,其实就是实现的多区域同步设计方案,只是在实施上是两地三中心。
为什么不是三地三中心?因为城市之间要通过光缆来传输数据,而这是一笔很大的开销。
功能列表:
- 用户“就近访问”
- 区域之间的数据同步
- 一个区域的服务器宕机后,流量自动打到其他区域
- 等
仅看这个功能列表,很多细节都很模糊(不是模糊,是根本就没有),我们先看设计方案,然后再把剩余的细节问题解决。
设计方案 #
两区域间单向的数据流 #
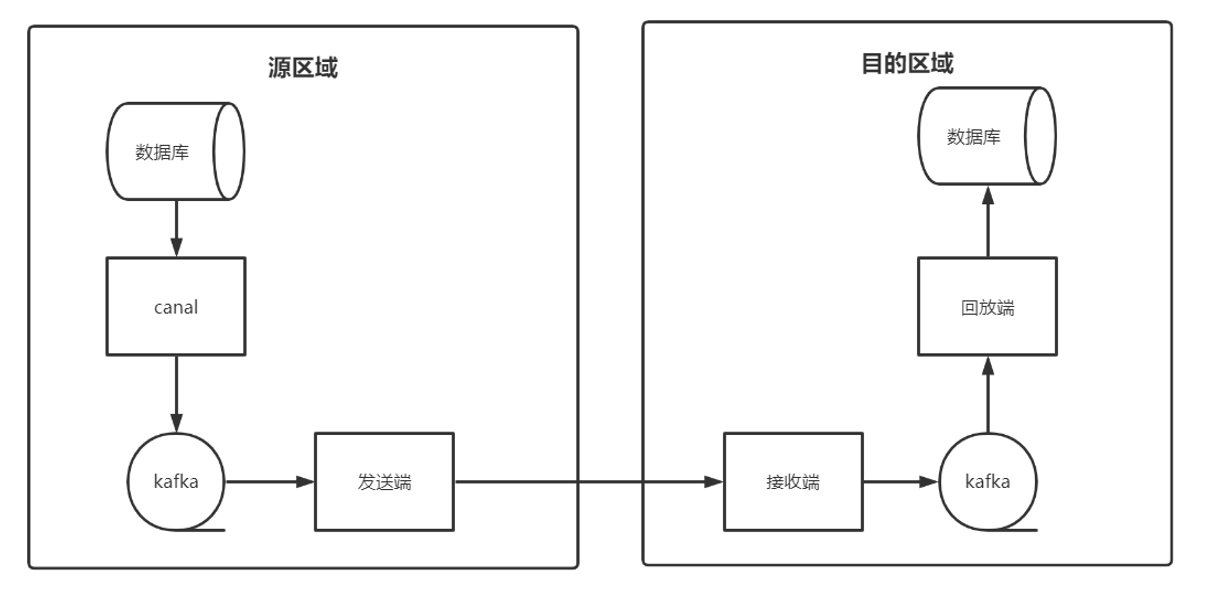
上图是区域之间数据的单向流动。
- 数据库的同步组件选择了阿里开源的canal,它会模拟从服务器来获取数据库的binlog
- canal支持tcp、kafka、rocketmq三种同步方式,我们选择kafka
- 发送端:主动发起同步的区域从kafka中获取到数据,然后发往被同步的区域
- 接收端:被同步的区域接收数据的服务即为接收端,接收到数据后会放到kafka中。这里kafka的作用是削峰与暂时的持久化。
- 回放端:从第四步中的kafka中获取数据,解析为sql,并执行,完成数据的回放
以上步骤解决了两个区域之间的单向同步
两区域间双向的数据流 #

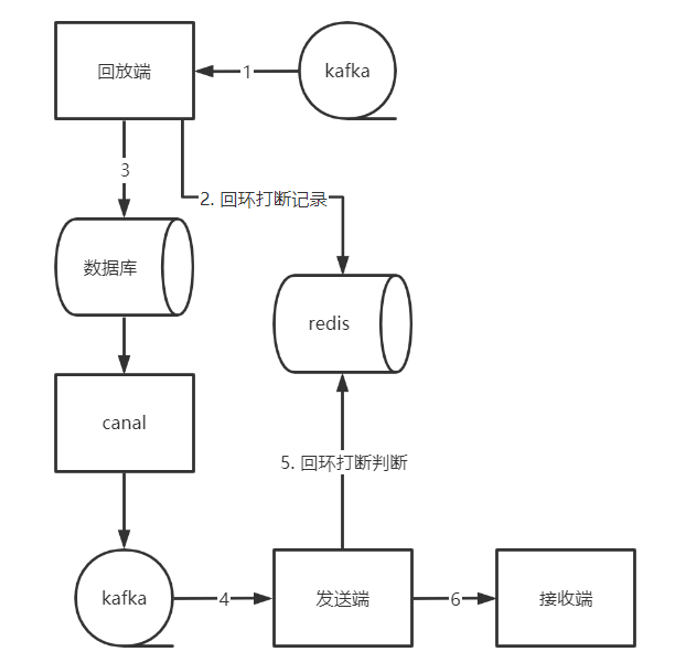
跟前一张图相比,只是进行了“镜像复制”,逻辑没有增加。
但是我们发现了数据回环——即从A区域的数据同步到B区域之后,又回到了A区域。如何打断数据回环?
一般来说,我们以“就近原则”为准,能在B区域打断就不要在A区域打断,这样至少能减少数据传输。
我们能控制得只有接收端、回放端和发送端,并且需要在入库之前打上标记,入库拿到数据之后进行过滤。根据“就近原则”,我们在回放端标记数据,在发送端进行数据过滤。具体方案如下:
将数据信息记录到redis的hash中,key为`replay:{数据库名}:{表名}`, field和value规则如下:
1. 对于DDL, field为crc32(sql)+区域标识, value为serverID
2. 对于插入, field为操作类型标识+主键ID+区域标识, value为来源serverID
3. 对于删除, field为操作类型标识+主键ID+区域标识, value为来源serverID
4. 对于更新, field为操作类型标识+主键ID+crc32(after)+区域标识, value为来源serverID
- 其中serverID为数据库实例的唯一标识,这里只来源实例。
- after为更新后的列数据,在实现中是一个结构体。插入和删除都是幂等的,因此不需要记录列信息,更新操作需要判断是否为同一条语句只用主键是不行的,所以需要记录列信息。
发送端从kafka获取到数据后,先判断数据是否是回环数据,如果是则过滤,然后删除缓存。
数据流向图如下:
三区域间双向的数据流 #
逻辑与两区域相同,只是图更难画。
区域宕机处理 #
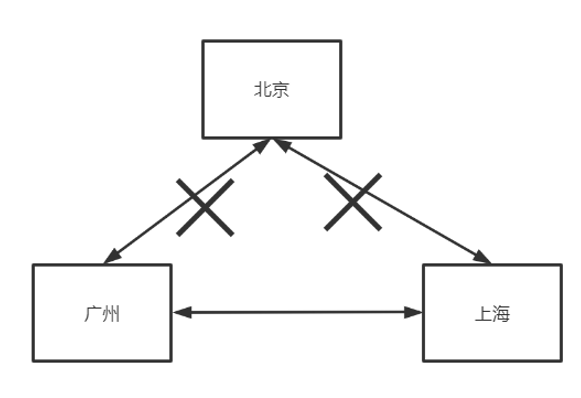
在多区域中,一个区域宕机会导致其他区域的数据不一致,这时候就要找到获得宕机区域数据最新的区域(实际上,更准确的表述应该是找到每个最新的数据库表,因为各个数据库表都是独立进行同步的),对数据缺失的其他区域进行补偿。那么如何找到这个数据最新的区域?
先了解下canal的机制:在canal的配置中,我们以数据库名作为topic,对表名进行哈希取模后作为分区存入kafka中,那么对一个表的消费情况通过偏移量offset即可确知。
但是不同区域同一个topic的同一个分区下,同一个offset对应的数据可能是不同的,这和canal中配置的binlog文件和偏移量有关。因此,记录消费位点,我们不能以本区域的kafka偏移量为准,而应该以其他区域的kafka偏移量为准。
这意味着发送端在发送数据时,需要将本条kakfa消息的位点告之接收端,接收端得到后,对其进行记录。
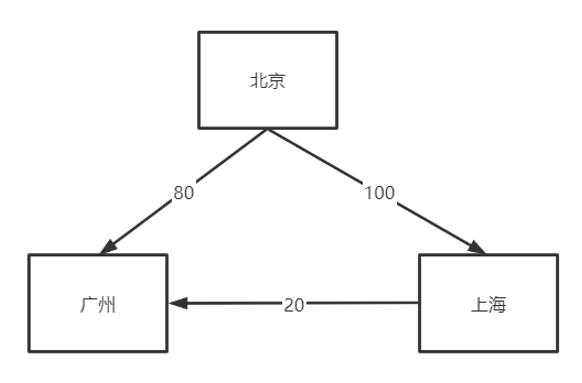
当北京区域宕机后:
- 广州区域记录表XXX中接收到北京区域的偏移量为80
- 上海区域记录表XXX中接收到北京区域的偏移量为100
那么我们就知道对于北京区域所同步的XXX表的数据而言,上海区域中表XXX的数据最新,因此我们需要将上海区域最新的这20条消息发给广州。
那怎样找到这20条消息呢?我们得到的位点是北京区域的,不是上海区域的。目前的解决方式是在接收端获取到数据时,将其写入到kafka中,这样就相当于进行了一份备份。对于这种备份,我们可以缩小kafka文件的保留时间来减少资源的消耗。
回想下整个过程,我们已经想好了区域宕机后的数据同步逻辑,但是如何得知区域宕机了呢?我们通过zookeeper进行监听。同时,zookeeper也是配置中心。
前端如何访问本区域 #
用户在访问时,网关会判断其所属区域,如果是本区域,则直接访问,如果不是,则告知其所属区域的地址,前端接收到该信息后,重新访问其所属区域的服务。
这里有个问题:一个区域是会崩溃的,如果用户访问的是崩溃的区域,那么就没办法访问了。因此前端需要记住三个区域的地址,如果一个区域访问不通,就访问另外的。
但这又产生了另外一个问题:区域A崩溃后,原属于区域A的用户的数据可能还没有完全同步到其他区域,这时数据是不一致的。所以我们在其同步完成前,是不允许其写入操作的,只能查看,即使看到的数据有些延迟,也不会差太多,并且很快就会同步完成。
因为断电等原因导致的区域崩溃,数据是肯定会丢失一些的,但是由于同步速度快于数据库的写入速度,因此我们能够最大程度上保护数据。
如何降低数据延迟 #
区域之间的数据同步延迟比较严重(相对来说),所以我们根据企业来源地来决定用户访问哪个区域的服务,并且能保证大部分用户能够得到准确的判断。
对于另外一些用户,比如去外地出差,我们暂时不做优化,还让他访问原区域的服务。因为这存在数据安全性问题。下面会讲。
数据安全性 #
在我们的设计中,三个区域都是可以写入的,并且需要互相同步,那么要如何保证三个区域之间的数据不冲突的?
- 对数据库的主键冲突问题:我们强制要求在数据表中使用UUID或者雪花ID作为主键
- 对于一个用户来说,因为他会一直访问一个区域的服务,因此对他来说不存在数据同步,但是对于一个企业来说,就不一样了,因为任何一个用户的变动都可能影响一个企业的数据。因此我们规定,对于一个企业下的用户,只能访问同一个区域下的服务,这是通过企业注册的地址来判断的。
崩溃后的区域恢复 #
区域崩溃后,其数据已经远远落后于其他区域。这时候如果还向之前那样,根据kafka的位点进行同步,对于数据的一致性是有很大不确定性的,比如崩溃的区域有些数据未同步到其他区域,这时候没有办法处理这些数据,因为用户可能已经又做了数据更改。
所以我们决定放弃不做区域恢复,重新进行区域的创建。
对接方案 #
哪些业务不可以做异地多活 #
对数据要求强一致性的业务,如涉及到金钱上的业务。对于这样的业务,再谨慎都是不为过的。
这里说的不做异地多活,是指对用户不做区域的切换,数据还是要同步的。
哪些业务可以做异地多活 #
以优先级由高到低进行罗列:
- 核心业务
- 能够给公司带来收益的业务
- 不要求数据强一致的业务
- 数据可恢复性强的业务:比如打卡