一致性哈希
Table of Contents
序言-我们要聊什么 #
- 当数据表中的数据量太多时,我们需要进行分表
- 当用户请求的数量太多时,我们需要进行分流
- 当一个结构需要存储很多数据时,为了加快访问速度,我们需要进行分片
这些都是对数据的“切分"。而完成”切分“最常用的方式就是对数据进行哈希取模。
这篇博客会从哈希取模讲起,然后探讨哈希重组(rehash)过程中遇到的问题,一致性哈希又如何解决的这些问题。
哈希取模 #
假设我们有10个数据(0-9),通过哈希取模可以相对平均的存入四个桶中,如下图所示:
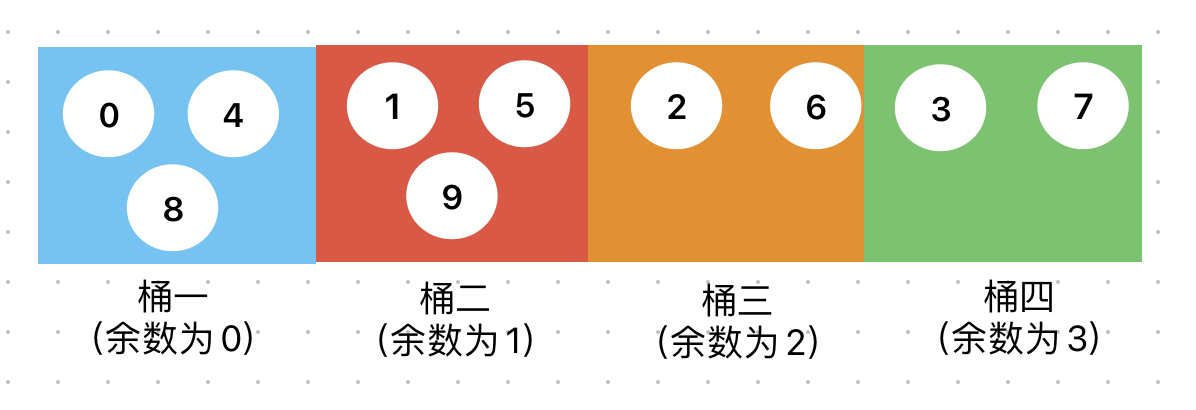
如果桶的数量不变,那么随着数据的增多,每个桶中的数据量会逐渐增多。在这个过程中,可能有以下几种需求:
- 增加新的桶:桶中的数据太多放不下了。
- 移除已有的桶:某个桶坏掉了。
增加新桶 #
还是以之前的10个数据为例,区别只在于桶变成了5个。这时候数据的分布如下:
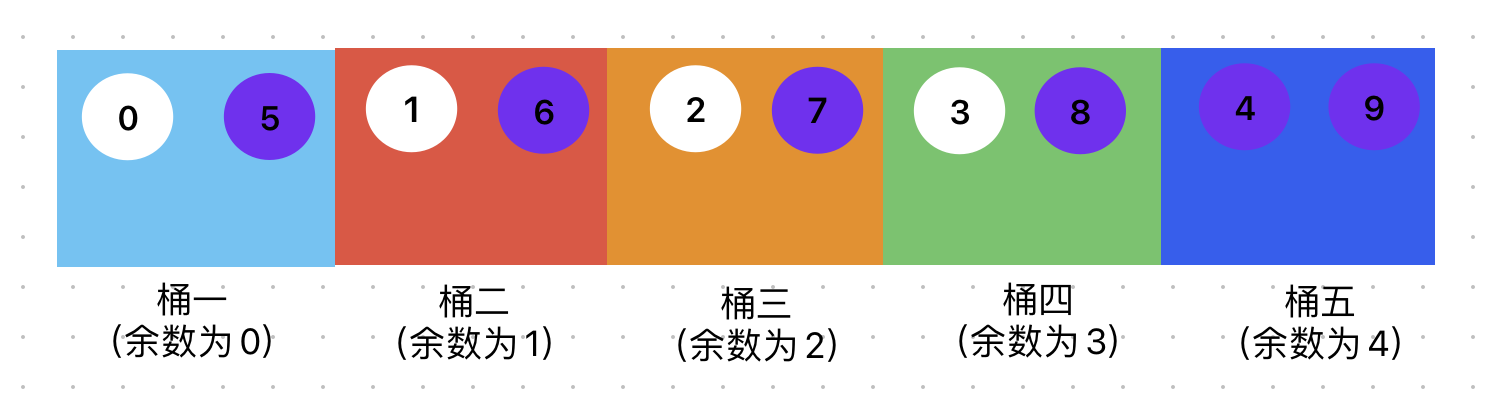
其中紫色的数据代表了需要进行迁移的数据,可以看到有6个,占总数的3/5。也就是说当新增桶后,大部分的数据都要进行迁移。
移除桶 #
现在在4个桶的基础上移除桶四,数据分布如下:

可以看到一共迁移了7个数据,占总数的7/10。也就是说当移除桶后,大部分数据都需要进行迁移。
缺点 #
上述哈希取模的方案在哈希重组的过程中表现的非常糟糕。如果是在现实中,这往往意味着需要停止服务!
一致性哈希 #
既然哈希重组那么糟糕,那么干脆不用好了!
一致性哈希提供了这样一种解决方案:
- 桶的数量选取一个足够大的数(比如2^32),这足以保证无需因数据量增大而新增桶。因为无需考虑新增桶,为了便于理解,我们将这2^32个桶围成一个环(如下图)。
- 对节点进行哈希取模,找到其在环中的位置。
- 数据会存储在其在环中顺时针查找到的第一个节点中。
在这个方案中,我们新增了“节点”这个概念,而节点其实就是之前例子中的桶,用于存储数据,这个方案中的桶则变成了一个抽象的概念,其本身只是一个“位置”而已。
如下图所示,我们用方形表示节点,用圆形表示数据:

移除节点 #
假设节点4损坏了,需要被移除,按照“节点查找规则”,数据9应迁移到节点1。如下图所示:
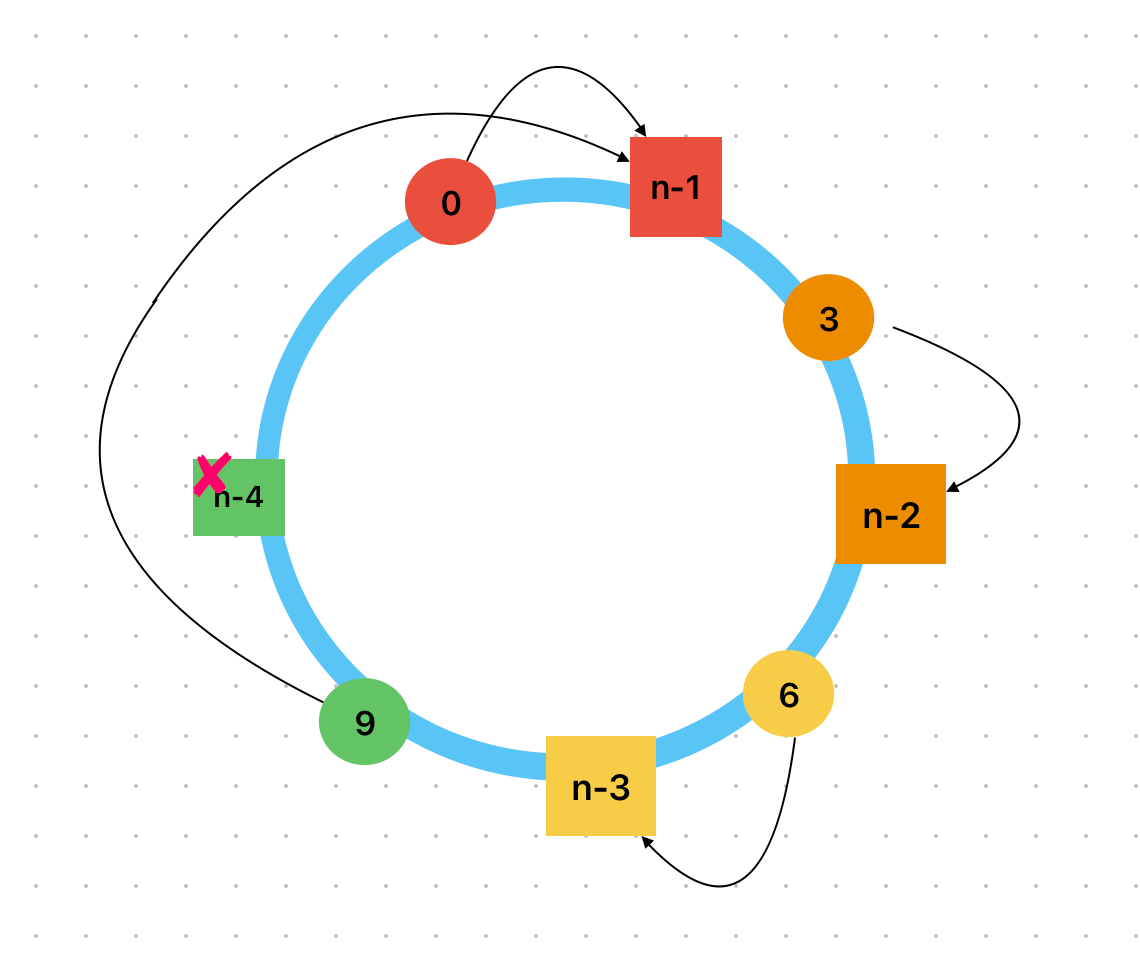
这个迁移过程中只移动了节点4上的数据,数据量为1,占总数据量的1/4,可以看到受影响的数据量少了很多!
增加新节点 #
我们修复了节点4,现在让我们把它加入进来吧。
可以看到,需要迁移的数据还是只有9。受影响的数据量极大的减少!
一致性 #
所谓的“一致性”,就是指在“节点重组”的过程中,数据尽量维持在原地不动!
这在大型的数据应用中,能够实现快速的数据重新分片。
缺点 #
上述方案的缺点在于节点可能是分布不均的,这会导致数据分布不均!
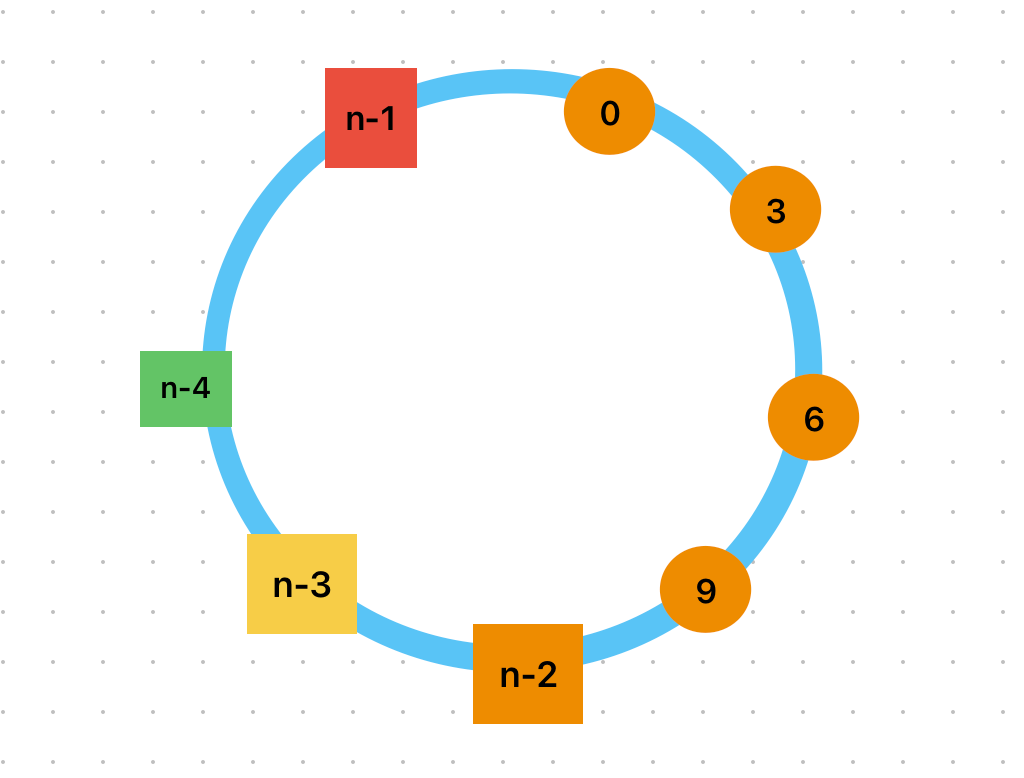
如上图所示,所有的数据都被分配到了节点2!
虚拟节点 #
为了解决分配不均的问题,我们需要设置大量的虚拟节点来保证节点足够均匀。
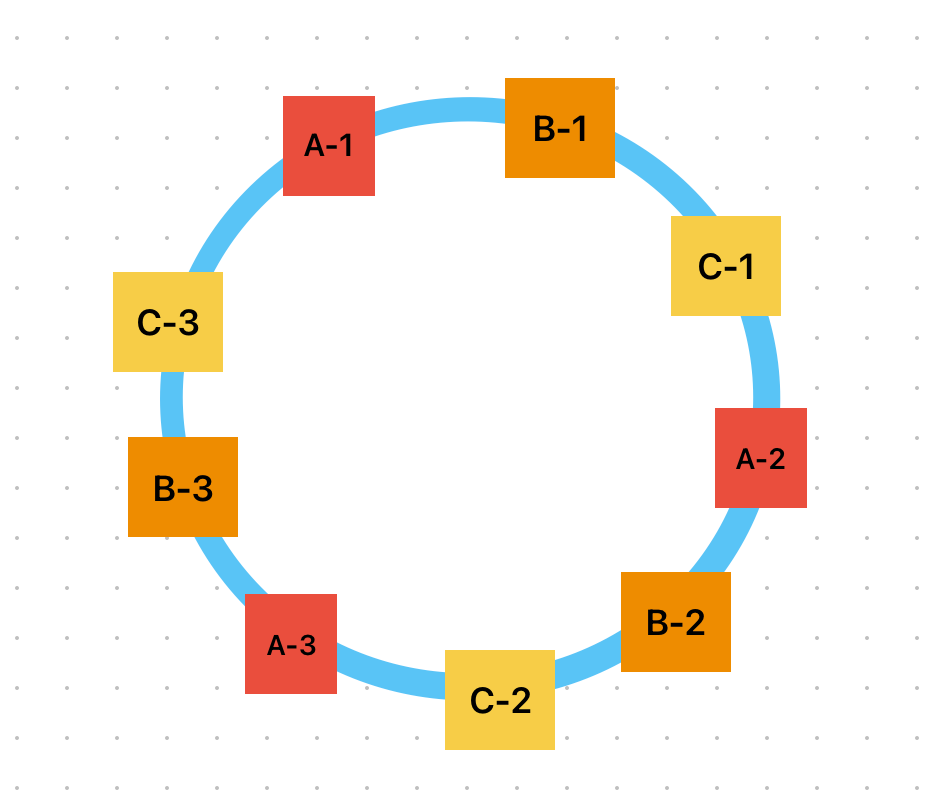
如上图所示,我们设置了9个虚拟节点(9个虚拟节点对应了3个真实节点),这些节点能够平均地分布于环中,这意味着数据也会平均的分布在节点中(假设经过哈希后数据均匀分布于环中)。
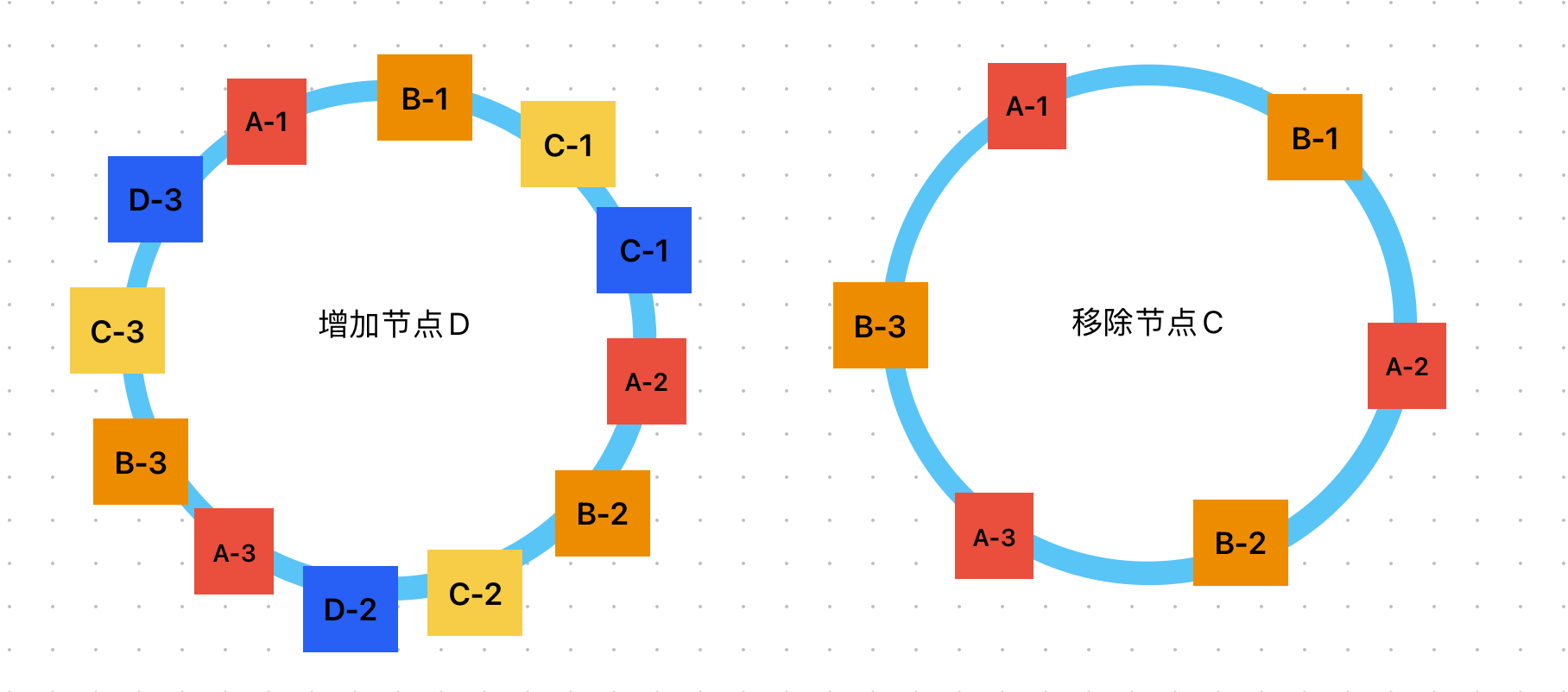
需要注意的时,这时候新增或者移除节点,对应的虚拟节点也要新增或移除:
小结 #
- 一致性哈希解决了“哈希重组”过程中需要迁移的数据量很大的问题。
- 一致性哈希的维护成本很高(相比简单的哈希取模),需要维护真实节点与虚拟节点的关系,虚拟节点与数据的关系。