通讯录同步-同步速度优化
Table of Contents
定义:问题是什么 #
- 企微、钉钉、飞书等平台为了保护自己的服务,都会有对应的限流策略。因此在第一版的的定时同步中,企业是一家一家同步的。这导致客户设置的中午12点同步,很可能在下午3点才开始同步。
- 在一家企业的同步流程中存在依赖关系,比如要先同步部门再同步员工。所以在第一版的定时同步中,部门和员工的同步是串行的,这导致员工较多的企业同步的时间较长。
目标:要解决哪些问题 #
- 首先要解决单个企业同步时间过长的问题。因为
- 这个影响测试同学的工作效率, 比如一次测试需要10分钟,那么一个小时也测不了几个场景。
- 直接影响客户的使用体验。比如客户点击了同步,却要等半个小时才能看到结果。
- 在解决上个问题的基础上,提供解决多企业串行同步的问题。
问题一:单个企业同步时间过长 #
串行改并行 #
解决【单个企业同步时间过长】的问题,首先考虑通过并发的形式去同步部门和员工。这就需要搞清楚同步内在的依赖关系。
搞清依赖关系 #
- 同步员工之前需要先同步其所属部门(所属部门可以有多个)
- 同步员工之前需要先同步其直属leader
- 同步部门之前需要先同步父部门
- 同步部门之前需要先同步部门负责人(部门负责人可以有多个)
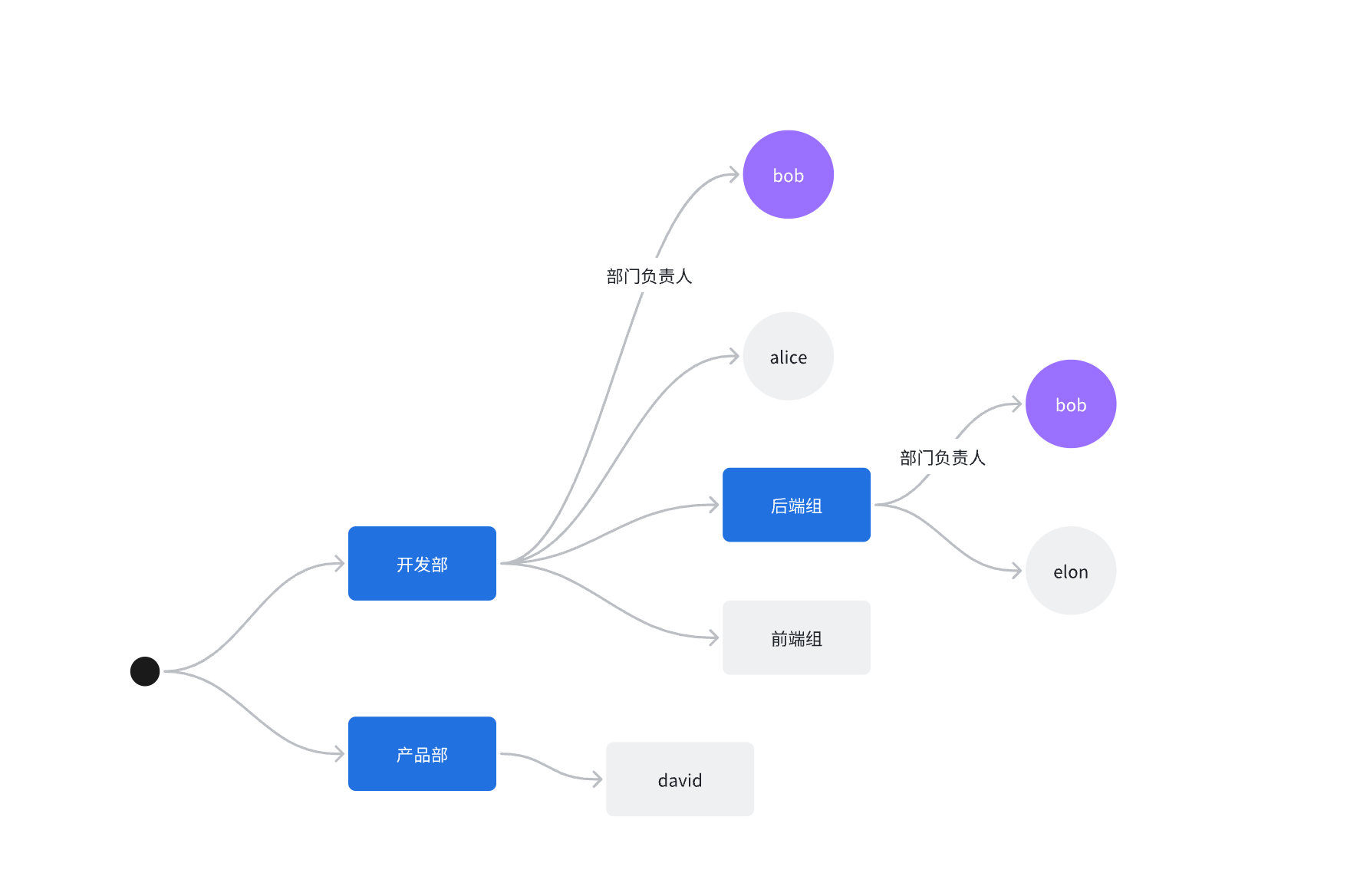
依赖循环 #
理想情况下,存在依赖关系的同步应该是一个有向无环图,但是实际上它是有环的:
-
部门同步需要先同步部分负责人,员工同步需要先同步所属部门。这里部门负责人和所属部门的同步就产生了一个环。
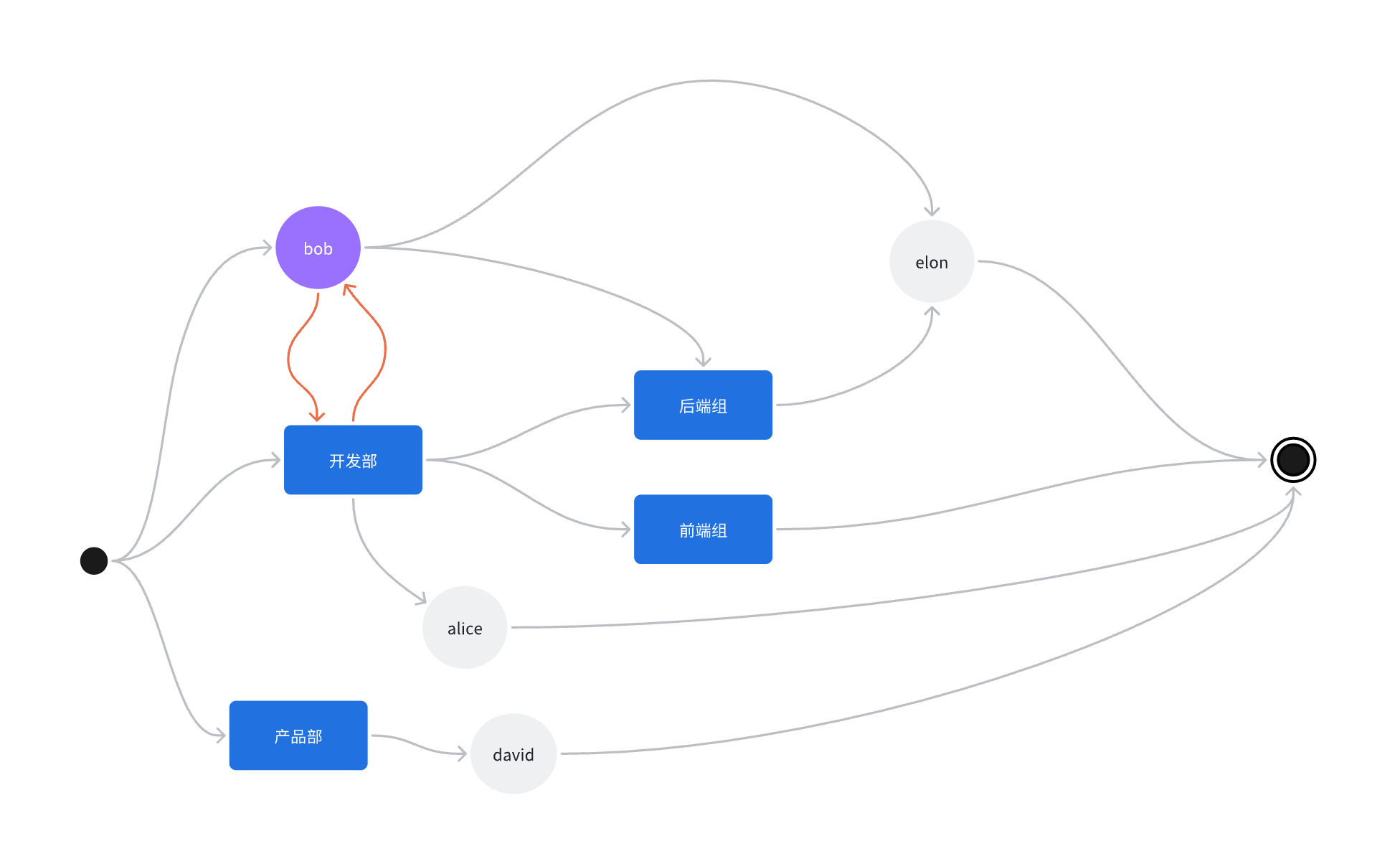
-
同步员工之前需要同步其直属leader,这个过程也可以产生一个环:A->B, B->C, C->A。
解决循环依赖 #
现在我们的同步关系是一个有向图,这个图是存在环的。环的存在会导致程序进入死循环: 同步部门时,要先去同步部门负责人,同步部门负责人时,要先去同步部门。
所以我们必须要去环。
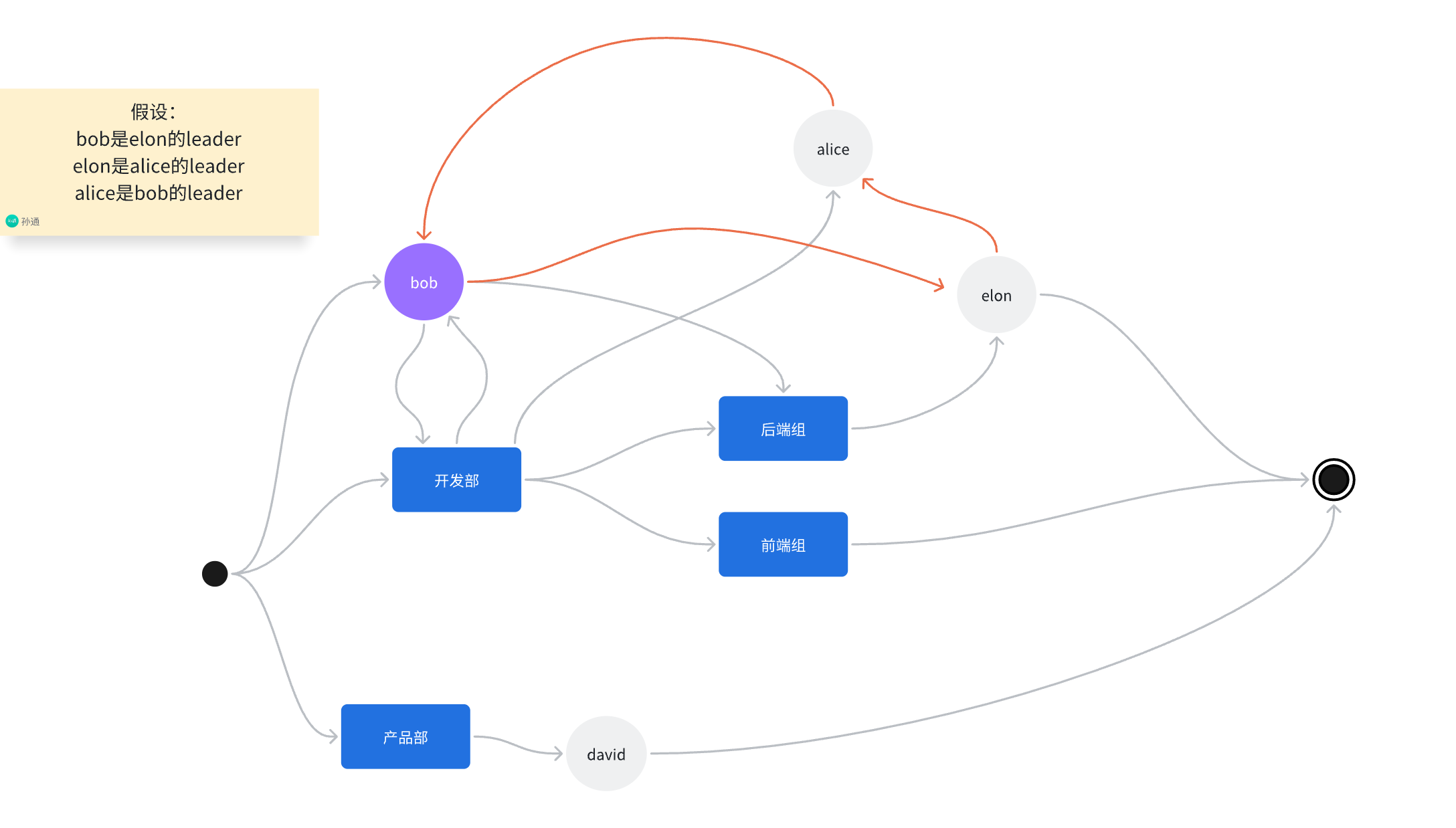
拆解 #
我们可以对循环依赖的部分进行拆解——先将部分信息剥离,先同步主要信息,最后同步剥离的信息:
- 对于依赖循环1,我们可以在同步部门时先不同步部门负责人,同步完部门和员工后再同步部门负责人。
- 对于依赖循环2,我们可以在同步员工时先不同步直属leader,同步完员工和部门后再同步直属leader。
当然,在同步时也要检查是否存在循环依赖,如果不存在,也就不需要进行拆分。
合并 #
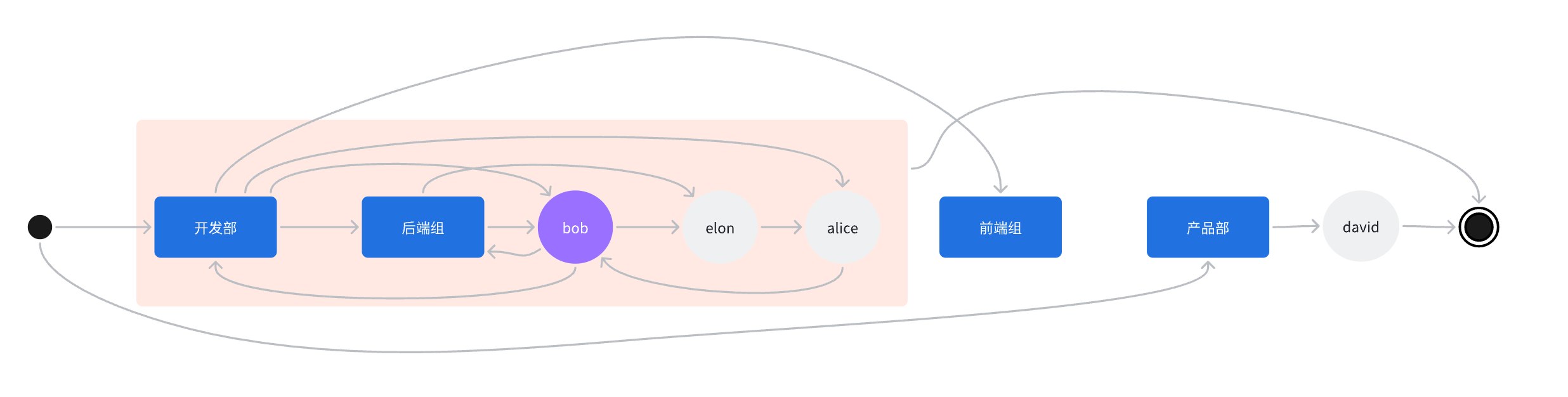
我们也可以将循环依赖的部分合并成一个节点,通过一个特殊的方法去处理这个节点。
处理逻辑:
- 通过递归找到”最小环“(合并的节点中可能存在多个环,并且存在嵌套关系,通过递归可以找到最小环)
- 判断造成环的原因:
- 如果是部门与部门负责人之间的环,则同步部门时先不同步部门负责人,同步完”最小环“后再同步部门的负责人字段
- 如果是员工直属leader之间的环,则随便找到”最小环“中的一个员工,先不同步其直属leader,同步完”最小环“后再同步这个员工的直属leader字段
- 递归以上两个过程,直到没有环为止。
相比较与拆解,合并的逻辑更加复杂,但是合并的逻辑更符合人的自然操作——换句话说就是更符合领域规则,这样做是有好处的, 比如说采用拆解的做法:
- 同步员工/部门后的需要记录同步日志以展示给客户。 正常情况下,同步完一个员工就记一个同步状态、员工标识,但是在同步剥离的信息时,就要判断这个员工/部门是否已经记录在册,如果已存在,就不要再记录
- 同步员工/部门后的需要更新同步进度,这个会在客户的页面展示一个进度条。进度的展示是根据当前同步的员工/部门数除以员工加上部门的总数得到的。这意味着在同步“剥离”的信息时,不应该更新这个进度,因为这个员工/部门已经在之前算进去了。所以用户的进度条会在后边“走的更慢”。
采用合并的做法,可以避免上述问题,因为我们是通过一个特殊的方法去处理这个造成循环的节点,在这个节点内部,我们知道哪些员工/部门需要记日志,并且进度计算也不会产生问题。
构造图 #
识别环 #
可以通过kosaraju算法或者Tarjan算法来识别环(强连通分量)。
异步同步 #
- 找到图中入度为0的节点(就叫它起始节点吧)
- 同步起始节点。如果这个节点是一个环,就将这个环的中节点信息以降级的方式同步(比如先不同步部门负责人身份&先不同步直属leader)。
- 同步完起始节点后,找到起始节点的下游节点。
- 判断下游节点所依赖的上游节点是否都已同步。一个节点可能依赖多个父级节点,如员工依赖部门节点以及直属leader节点。
- 如果父级节点都已同步,直接同步该节点。
- 如果父级节点存在未同步的情况,将该节点放入【待同步池】中。
- 每同步完一个节点,判断【待同步池】中是否有依赖该节点的下游节点,如果有并且该下游节点所有依赖的父级节点已同步,同步该下游节点
- 同步完节点后,找到其下游节点,并执行步骤5.
避免重复同步 #
在同步一家企业的部门和员工时,理想状态下,如果一个部门和员工已经做过同步并且没做更改,就不需要再次同步。
也就是说,我们需要一个手段来检测员工/部门是否有变更。
哈希 #
我们可以把员工/部门的信息做成一个哈希,保存在数据库中。每次同步前,比较最新的信息的哈希值与之前的哈希值是否相同,相同的则说明信息未变更,因此无需同步。
这样做的缺点就是需要存储的哈希值很多:一家一万人的企业,就需要存储一万个哈希值(考虑到部门数应远小于员工数,因此在计数时可忽略部门的影响)。
默克尔树 #
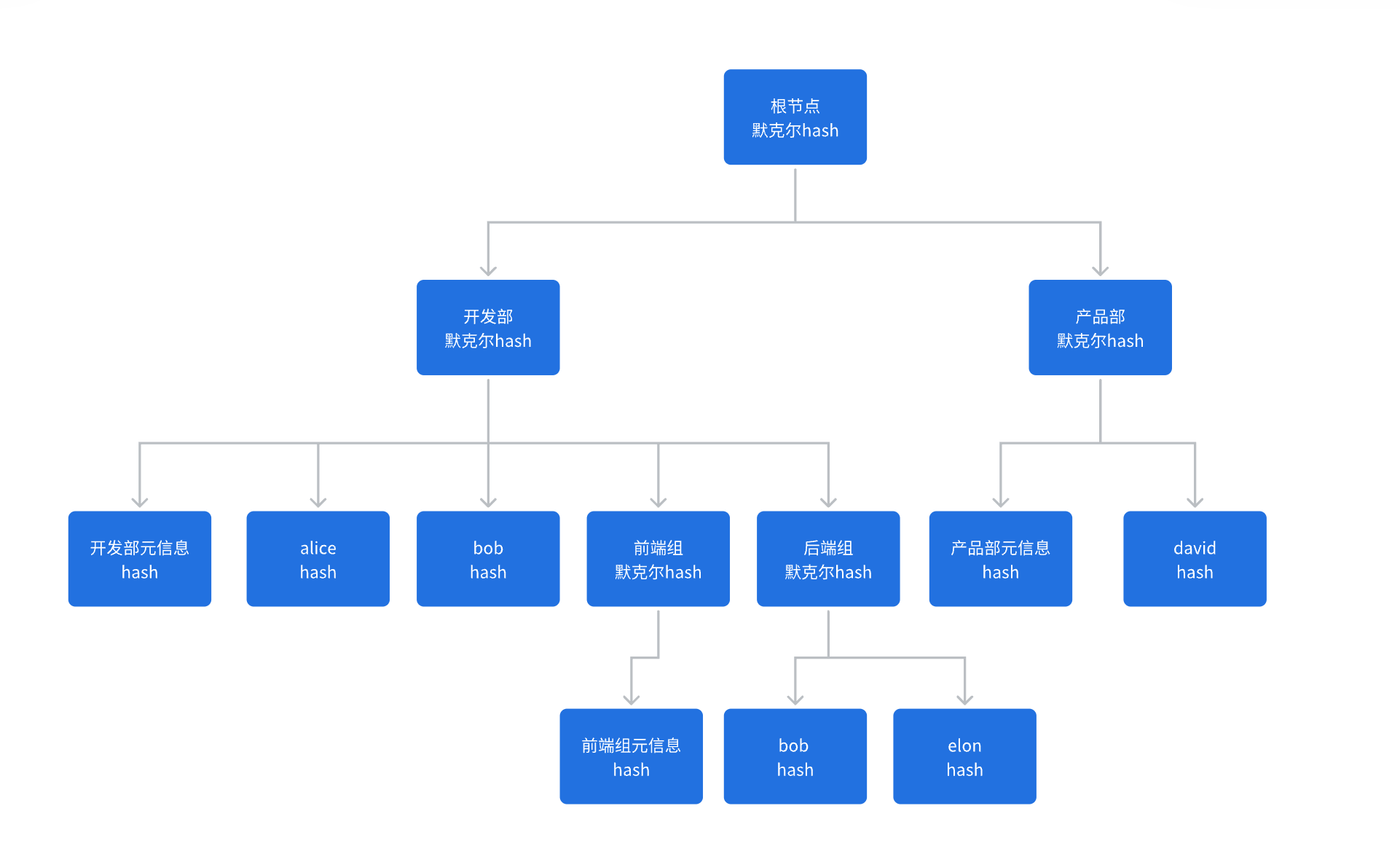
默克尔树的特点就是通过不断合并哈希值,从而减少存储的哈希值的数量。使用默克尔树,我们存储的哈希值数量不再是员工数+部门数,而只是部门数。考虑到部门数应远小于员工数,这种方式能够节省不少存储空间。
采用默克尔树的另一个优点就是可以节省大量的对比时间——如果部门的哈希值相同,那么其子部门以及子部门下的员工的信息一定相同。因此对于实际场景(企业的员工、部门信息不会频繁变更),可节省大量的同步时间。
默克尔树构造 #
我们的默克尔树有如下特点:
- 默克尔树的节点实际上与部门树的节点一一对应。
- 根节点是公司(如果设置了同步范围,那就是多个部门+员工)
- 子节点是部门和员工。
- 如果子节点是部门,那么这个部门可以是叶子节点,也可以是非叶子节点。
- 如果子节点是员工,那么员工是叶子节点。
默克尔树要求子节点是有序的,因为顺序会影响哈希值的计算。而子节点顺序只影响父节点的哈希值,因此通过ID进行排序即可(员工和部门一定存在ID)。
默克尔哈希值的计算 #
- 递归部门树
- 对一个部门节点,获取部门信息的哈希值、员工信息的哈希值以及子部门的默克尔哈希值
- 通过ID对员工和部门排序,然后将其对应的哈希值按顺序拼接成一个字符串,然后对这个字符串取哈希,这个哈希就是父部门的默克尔哈希值。
员工/部门信息的哈希值的计算方式是:将员工/部门信息的字段按顺序拼接成一个字符串,然后对这个字符串取哈希。
信息变更检测的必要性 #
在之前的版本,我们没有检测信息是否变动,仅仅是通过映射关系找到同步双方的两个实体(部门或员工),然后比对每个字段是否相同。
现在我们是通过计算哈希值来判断信息是否变更。也就是说我们将查找实体并对比字段的过程改成了计算哈希并对比的过程。这个优化并不能带来多少性能提升,但是它代表了一种业务规则:如果已同步并且信息未变更,那么就无需再次同步。
服务商接口访问频率限制 #
服务商对接口的访问频率有限制,超过这个限制会被禁止在短时间内再次访问,因此我们需要控制访问的频率。
所以我们需要实现一个限流器,这个限流器的实现包括:
- 通过装饰器模式对服务商接口进行封装。
- 通过令牌桶算法控制访问频率。
- 如果拿不到令牌,就等待,直到拿到令牌为止。
- 通过redis来实现分布式的令牌桶算法。
即使我们能够保证访问服务商的接口不会超过频率限制,但是过多的并发还是会导致同步之间的互相阻塞,这一点在定时同步时多企业并行同步时会很明显。
问题二: 多企业串行同步 #
解决完问题一后,多企业已经可以并行同步了。需要注意的点是如何控制同步企业的并发数量。这与每个服务商的频率限制策略有关。
数据量预估 #
我们保守估计,平均每家企业有6000次服务商接口请求, 这些请求会在1分钟内跑完,也就是说一家企业平均每分钟会访问1000次。
钉钉 #
钉钉的频率限制策略是分两个维度:
- 每个IP调用所有接口总量,最高20秒10000次。
- 每个应用,对每个授权企业,调用每个接口,最高频率40次/秒。
那么:
- 对于授权企业的维度,每分钟最多访问2400次。这对于我们的预估是足够的。
- 对于IP的维度,假设我们只有一个出口IP,一分钟最多30000次,而我们一家企业需要一分钟1000次,因此可以最多有30家企业并发同步。
企微 #
企微也是对应的限制策略:
- 每企业调用单个cgi/api不可超过1万次/分,15万次/小时
- 第三方应用提供商每ip调用单个cgi/api不可超过4万次/分,120万次/小时
那么:
- 从企业的维度来看,虽然要比钉钉的限制更严格,但是由于我们的总量会控制在1万次以内,因此也不会超过企微的限制。
- 从第三方应用提供商的维度来看,我们按照1小时的120万次来算,每分钟最多有2万次访问,平均一家企业每分钟1000次,那么最多并发同步的企业数量是20家。
因此,根据不同的服务商,设置不同的企业并发数量即可。