《Professor Frisby's Mostly Adequate Guide to Functional Programming》
Table of Contents
前言 #
这是我第二次读这本书。
第一次读的时候就感觉函数式编程很有意思,但是由于日常代码使用go,而go作为静态语言不能实现柯里化,因此仍使用面向对象(这其实是一个错误,柯里化不是函数式编程的全部)。
后边学习Rust时了解到Rust的部分实现借鉴了函数式编程的思想,所以又把这本书拿起来了(虽然Rust也不能实现柯里化🤣)。
在这本书里,作者使用了javascript作为开发语言进行了示例,并介绍了数学定律来供数学家们(即使用函数式编程的程序员)排列组合这些公式(即函数)。时刻牢记这些定律能够优化代码,让代码更简洁、更高效。
基本概念 #
为了避免遗忘,还是简单介绍下书里介绍的一系列函数式编程的概念吧。
柯里化(currying) #
通过柯里化,我们可以将一个接受多个参数的函数转换为一系列只接受一个参数的函数。这种转换过程是逐步的,每一步都会返回一个新的函数,这个函数接受一个参数,并返回一个新的函数。这个过程会一直持续到所有参数都被处理完。
const add = (x) => (y) => x + y;
const incrementOne = add(1);
incrementOne(2); // 3
incrementOne(7); // 8
这意味着我们无需定义参数类型为数组的函数——通过map来映射数组中的元素,通过柯里化来执行逻辑。
const list = [1, 2, 3, 4, 5];
list.map(incrementOne); // [2, 3, 4, 5, 6]
map本身也是柯里化的:const map = curry((f, xs) => xs.map(f));
对于批量操作能够提升性能的场景(查询数据API)还是老老实实定义参数为数组类型吧
上边是javascript的例子,可以用python实现:
def curry(func):
def curried(*args, **kwargs):
if len(args) + len(kwargs) >= func.__code__.co_argcount:
return func(*args, **kwargs)
return lambda *more_args, **more_kwargs: curried(*(args + more_args), **{**kwargs, **more_kwargs})
return curried
@curry
def add(x, y, z):
return x + y + z
add1 = add(1)
add12 = add1(2)
result = add12(3)
print(result) # Output should be 6
或者使用toolz(python里函数式编程的工具):
from toolz import curry
@curry
def add(x, y, z):
return x + y + z
add1 = add(1)
add12 = add1(2)
result = add12(3)
print(result) # Output should be 6
组合(compose) #
组合是指将多个函数合并为一个函数。这个函数会依次执行每个函数,并将前一个函数的返回值作为后一个函数的参数。这种方式能够让我们避免嵌套函数调用。
const head = (x) => x[0];
const reverse = reduce((acc, x) => [x, ...acc], []);
// 定义一个数组
var ids = [1, 2, 3, 4, 5];
// 非组合的方式
head(reverse(ids));
// 组合的方式
const last = compose(head, reverse);
last(ids);
通过组合,我们可以更自由的组织函数,从而更容易的理解和维护代码。就像堆积木一样。
Pointfree风格 #
通过上面的例子可以看到,在最终执行函数之前,实际数据(ids)都没有掺和到业务逻辑中(获取last)。这使得整体的代码更清晰,这种风格叫做Pointfree。
在函数式编程中,Pointfree风格非常受欢迎,因为我们实际上是在区分有副作用的代码和无副作用的代码,无副作用的代码更稳定,而有副作用的代码则需要“特殊关照”(但实际编程中,业务逻辑是更重要的,且不应该产生副作用,因此抽离出来能够让代码更加清晰、更容易维护)。
在函数式编程中,函数就像流水线一样排列、执行,彼此之间又可以通过组合抽象。
自由的组合 #
在函数式编程中,我们通过柯里化实现了函数只有一个入参,一个输出,这使得函数之间可以自由的组合,就像贪吃蛇那样,每个小蛇自由组合,然后最终合并成一个整体!!!
const loudLastUpper = compose(exclaim, toUpperCase, head, reverse);
// -- or ---------------------------------------------------------------
const last = compose(head, reverse);
const loudLastUpper = compose(exclaim, toUpperCase, last);
// -- or ---------------------------------------------------------------
const last = compose(head, reverse);
const angry = compose(exclaim, toUpperCase);
const loudLastUpper = compose(angry, last);
// more variations...
Container #
Container是一个对象,用来存储一个值。
class Container {
constructor(x) {
this.$value = x;
}
static of(x) {
return new Container(x);
}
}
of #
of方法用于创建一个新的Container。
of 与new不同,of更偏向于数学中的集合概念,代表的是一个集合的子集,而new则更像是面向对象的概念,用于创建一个新的对象。
Maybe #
Maybe用于处理可能为空的值。
class Maybe {
static of(x) {
return new Maybe(x);
}
get isNothing() {
return this.$value === null || this.$value === undefined;
}
constructor(x) {
this.$value = x;
}
map(fn) {
return this.isNothing ? this : Maybe.of(fn(this.$value));
}
inspect() {
return this.isNothing ? "Nothing" : `Just(${inspect(this.$value)})`;
}
}
Maybe的设计与Rust中的Option相同。Option是一个枚举值,只包含两个变体:None和Some(T)
Maybe的存在能够让代码免于处理null值。为空检查是非常恼人的:有时候你知道返回值一定不为空,但是为了后续代码迭代可能会允许它为空,为了避免这种情况,你只能去兼容为空的场景。
// safeHead :: [a] -> Maybe(a)
const safeHead = (xs) => Maybe.of(xs[0]);
// streetName :: Object -> Maybe String
const streetName = compose(map(prop("street")), safeHead, prop("addresses"));
streetName({ addresses: [] });
// Nothing
streetName({ addresses: [{ street: "Shady Ln.", number: 4201 }] });
// Just('Shady Ln.')
Either #
Either用于处理"分叉"场景,Left表示一种场景,Right表示另一种场景。一般可用来处理错误—它包含两种类型:Left表示有值,Right表示产生了错误,不存在既有值有存在错误的情况。
class Either {
static of(x) {
return new Right(x);
}
constructor(x) {
this.$value = x;
}
}
class Left extends Either {
map(f) {
return this;
}
inspect() {
return `Left(${inspect(this.$value)})`;
}
}
class Right extends Either {
map(f) {
return Either.of(f(this.$value));
}
inspect() {
return `Right(${inspect(this.$value)})`;
}
}
const left = (x) => new Left(x);
Either表示两种可能得结果,也产生了两种处理流程。
const moment = require("moment");
// getAge :: Date -> User -> Either(String, Number)
const getAge = curry((now, user) => {
const birthDate = moment(user.birthDate, "YYYY-MM-DD");
return birthDate.isValid()
? Either.of(now.diff(birthDate, "years"))
: left("Birth date could not be parsed");
});
getAge(moment(), { birthDate: "2005-12-12" });
// Right(9)
getAge(moment(), { birthDate: "July 4, 2001" });
// Left('Birth date could not be parsed')
Either与Rust中的Result的设计相似。Result是一个枚举值,只包含两个变体:Ok(T)和Err(E)
Either能够避免一堆的错误判断: 如果你写go的话,会发现代码中存在大量的if err != nil {...}.
IO #
IO区别于Container,它存储的是一个函数,而不是一个值。IO的存在是为了处理副作用。
class IO {
constructor(io) {
this.unsafePerformIO = io;
}
map(fn) {
return new IO(compose(fn, this.unsafePerformIO));
}
}
用IO包裹存在副作用的函数:
// url :: IO String
const url = new IO(() => window.location.href);
// toPairs :: String -> [[String]]
const toPairs = compose(map(split("=")), split("&"));
// params :: String -> [[String]]
const params = compose(toPairs, last, split("?"));
// findParam :: String -> IO Maybe [String]
const findParam = (key) =>
map(compose(Maybe.of, find(compose(eq(key), head)), params), url);
// -- Impure calling code ----------------------------------------------
// run it by calling $value()!
findParam("searchTerm").$value();
// Just(['searchTerm', 'wafflehouse'])
Task #
Task用于处理异步任务,它与IO类似,只是Task是异步的。
// -- Pure application -------------------------------------------------
// blogPage :: Posts -> HTML
const blogPage = Handlebars.compile(blogTemplate);
// renderPage :: Posts -> HTML
const renderPage = compose(blogPage, sortBy(prop("date")));
// blog :: Params -> Task Error HTML
const blog = compose(map(renderPage), getJSON("/posts"));
// -- Impure calling code ----------------------------------------------
blog({}).fork(
(error) => $("#error").html(error.message),
(page) => $("#main").html(page),
);
$("#spinner").show();
Monads #
函数式编程中使用大量”复合“的结构(函子),比如:Maybe,IO,Either等,这些结构在实际场景中又会彼此嵌套,导致获取值或者操作值非常复杂。
Monads的目的就是合并相同类型且嵌套的函子。
join #
通过join来合并两个函子:
const mmo = Maybe.of(Maybe.of("nunchucks"));
// Maybe(Maybe('nunchucks'))
mmo.join();
// Maybe('nunchucks')
一个复杂的例子:
// log :: a -> IO a
const log = (x) =>
new IO(() => {
console.log(x);
return x;
});
// setStyle :: Selector -> CSSProps -> IO DOM
const setStyle = curry((sel, props) => new IO(() => jQuery(sel).css(props)));
// getItem :: String -> IO String
const getItem = (key) => new IO(() => localStorage.getItem(key));
// applyPreferences :: String -> IO DOM
const applyPreferences = compose(
join,
map(setStyle("#main")),
join,
map(log),
map(JSON.parse),
getItem,
);
applyPreferences("preferences").unsafePerformIO();
// Object {backgroundColor: "green"}
// <div style="background-color: 'green'"/>
chain #
观察上面这个例子, 每个join都配合一个map使用。为什么不把这两者再进行封装呢?
// chain :: Monad m => (a -> m b) -> m a -> m b
const chain = curry((f, m) => m.map(f).join());
// or
// chain :: Monad m => (a -> m b) -> m a -> m b
const chain = (f) => compose(join, map(f));
于是上一个例子就可以简化为:
const applyPreferences = compose(
chain(setStyle("#main")),
chain(log),
chain(JSON.parse),
getItem,
);
Applicative Functors #
Monads能够合并相同类型且嵌套的函子,但是对于“平级”的函子就没办法了。
函数式编程中可以通过一些手段来直接操作两个函子那的值。
ap #
ap是一个函数,能够将一个函子的值直接作用于另一个函子的值。
Container.of(add(2)).ap(Container.of(3));
// Container(5)
// all together now
Container.of(2).map(add).ap(Container.of(3));
// Container(5)
更抽象的表达为:
F.of(x).map(f) === F.of(f).ap(F.of(x));
现在,如果函数有多个参数,可以使用ap来链式调用:
// $ :: String -> IO DOM
const $ = (selector) => new IO(() => document.querySelector(selector));
// getVal :: String -> IO String
const getVal = compose(map(prop("value")), $);
// signIn :: String -> String -> Bool -> User
const signIn = curry((username, password, rememberMe) => {
/* signing in */
});
IO.of(signIn).ap(getVal("#email")).ap(getVal("#password")).ap(IO.of(false));
// IO({ id: 3, email: 'gg@allin.com' })
liftA2 & liftA3 #
可以使用liftA2或者liftA3来简化多个ap的链式调用:
const liftA2 = curry((g, f1, f2) => f1.map(g).ap(f2));
const liftA3 = curry((g, f1, f2, f3) => f1.map(g).ap(f2).ap(f3));
// liftA4, etc
上面的例子可以简化为:
liftA3(IO.of(signIn), getVal("#email"), getVal("#password"), IO.of(false));
ap,map,chain之间的关系 #
// map derived from of/ap
X.prototype.map = function map(f) {
return this.constructor.of(f).ap(this);
};
// map derived from chain
X.prototype.map = function map(f) {
return this.chain((a) => this.constructor.of(f(a)));
};
// ap derived from chain/map
X.prototype.ap = function ap(other) {
return this.chain((f) => other.map(f));
};
Natural Transformation #
自然转换是一个操作容器(一般是函子)的函数,用于将一个容器转换为另一个容器,
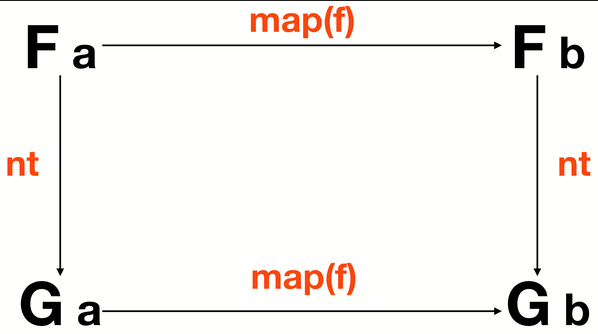
// nt :: (Functor f, Functor g) => f a -> g a
compose(map(f), nt) === compose(nt, map(f));
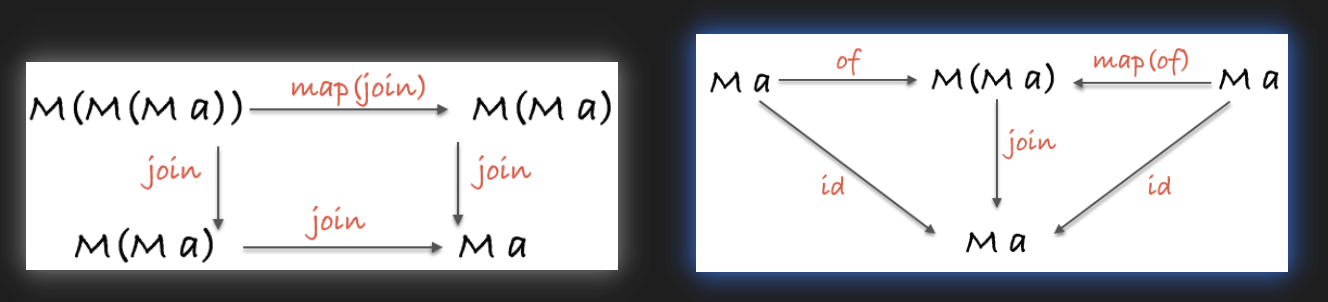
定律 #
结合律 #
compse #
// associativity
compose(f, compose(g, h)) === compose(compose(f, g), h);
// map's composition law
compose(map(f), map(g)) === map(compose(f, g));
注意第二个定律,Rust里的迭代器就是这样的:对于同一个迭代器进行两次
map,就等同于对这个迭代器迭代一次,对迭代器的每个元素依次执行f,g.
let arr = vec![1, 2, 3, 4, 5];
let f = |x| x + 1;
let g = |x| x * 2;
let result = arr.iter().map(f).map(g).collect::<Vec<_>>();
// or
let result = arr.iter().map(|x| g(f(x))).collect::<Vec<_>>();
join #
compose(join, map(join)) === compose(join, join);
ap #
A.of(compose).ap(u).ap(v).ap(w) === u.ap(v.ap(w));
同一性 #
compose #
// identity
map(id) === id;
(compose(id, f) === compose(f, id)) === f;
// identity for all (M a)
(compose(join, of) === compose(join, map(of))) === id;
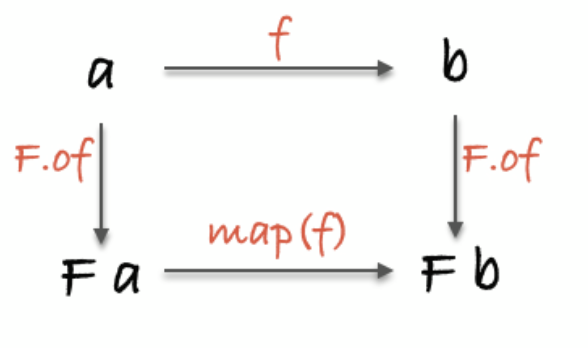
id就像"透明"一样,对于任何函数,id都不会改变其结果。
const mcompose = (f, g) => compose(chain(f), g);
// left identity
mcompose(M, f) === f;
// right identity
mcompose(f, M) === f;
// associativity
mcompose(mcompose(f, g), h) === mcompose(f, mcompose(g, h));
ap #
// identity
A.of(id).ap(v) === v;
// homomorphism
A.of(f).ap(A.of(x)) === A.of(f(x));
交换律 #
ap #
// interchange
v.ap(A.of(x)) === A.of((f) => f(x)).ap(v);
nt #
// nt :: (Functor f, Functor g) => f a -> g a
compose(map(f), nt) === compose(nt, map(f));
命令式 vs 声明式 #
很多书籍、博客里都表示声明式的代码要优于命令式的代码,为什么是这样呢?
代码示例 #
// 命令式
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
// 声明式(函数式)
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
声明式常见的形式,就是将实现细节隐藏在函数中,然后通过函数之间的组装来完成逻辑。
但声明式与命令式的区别仅仅是函数之间的组合吗? 命令式的代码也是可以有函数的封装,比如:
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
contain_and_push(line, query, &mut results)
}
results
}
pub fn contain_and_push<'a>(line: &'a str, query: &str, results: &mut Vec<&'a str>) {
if line.contains(query) {
results.push(line);
}
}
在命令式的代码中,我们通过抽象出contain_and_push函数,使得代码更简洁,但这仍是命令式的代码。
为什么推崇声明式? #
很多书籍、文章都会推荐声明式的写法。原因也很统一——无副作用!
什么是副作用?上述代码中for循环产生的变量line就是副作用(emmm,或许叫副产品会更好理解)。
我们可以定义: 在函数执行过程中产生了一个新的变量,并且这个变量会影响结果, 我们就称其为副作用.
如果你觉得这个例子不够好,一个for循环产生的变量能有什么副作用?嘿嘿,参考一下下边这个例子:
package main
import "fmt"
func main() {
var n *int
for i, v := range []int{1, 2, 3} {
if i == 1 {
n = &v
}
}
fmt.Println(*n)
}
以上这个go程序会输出什么?答案是取决于版本,如果是1.22及之后的版本会输出2,之前的版本会输出3.🐶🐶
我觉得这个例子很好的说明了什么是副作用!😅😅
所以我们说声明式风格的代码没有副作用就是指其不会产生影响结果的新的变量,没有副产品自然就没有副作用!!!
让我再解释下为什么上面这个有问题的代码在声明式的代码中不会有问题。我们当然也可以封装一个filter函数:
package main
import "fmt"
func main() {
match := func(idx int) bool {
return idx == 1
}
n := filter([]int{1, 2, 3}, match)
fmt.Println(*n)
}
func filter(arr []int, match func(idx int) bool) *int {
for i, v := range arr {
if match(i) {
return &v
}
}
return nil
}
但是我们不会这样去做(尽管这个代码程序执行上是没问题的),因为这个filter的设计(返回指针类型)违反了函数设计直觉。”公式“应该是既简单又优雅,并且是经过测试校验,不应该有问题的。
阅读体验 #
两种风格的代码,阅读体验是不一样的。阅读命令式的代码就像在俯视一个运行中的机器一样,需要观察每一个细节以保证机器的正常运行;而阅读声明式的代码就像是在阅读数学公式一样,需要搞清楚“公式”之间的组合方式。
所以有些人会吐槽函数式编程的代码难以阅读,因为他们习惯把重心放在细节实现上,所以在阅读时既要阅读函数的细节实现又要同时顾虑函数的组合方式,这样体验自然不会好。但是命令式的代码顺序的展示出了代码细节,阅读体验非常顺畅(如果不考虑引入的“副作用”导致的心智负担的话)。
而对于“数学家”来说,公式是不会出错的,所以他们只需要关心公式之间的组合即可。
有些命令式风格的拥簇者会说“代码是写给人看的”来表达对函数式编程的抵触。这句话是对的,但是这句话并不是绝对的。代码是写给人看的,但是不同的人有不同的阅读方式。习惯声明式代码风格的人阅读命令式风格的代码也会很难受。😆
函数式编程中的声明式 #
函数式编程中的声明式编程是另一个维度的东西:
// imperative
const authenticate = (form) => {
const user = toUser(form);
return logIn(user);
};
// declarative
const authenticate = compose(logIn, toUser);
在命令式风格中,我们说鉴权的过程就是先通过toUser将form转换为user,然后再通过logIn登录。而在声明式风格中,我们说验证的过程就是转换user并登录的组合。
静态语言中的函数式编程 #
由于静态语言要求在编译阶段必须确认变量的数据类型,因此很多函数式编程的特性难以实现。比如说Go, Rust难以实现柯里化; 相反,Python,Javascript这种动态类型的语言就能够实现。
但是我们不能因为某些特性无法使用就完全放弃函数式编程。因为函数式编程的本质是通过无副作用来保证代码质量, 而静态语言都能够在一定程度上使用这种“无副作用”的思想。
Rust #
Rust借鉴了很多函数式编程的思想,尤其是Haskell语言。比如说它的迭代器:
fn main() {
let numbers = vec![1, 2, 3, 4, 5];
let squared: Vec<_> = numbers.iter().map(|n| n * n).collect();
println!("{:?}", squared); // prints [1, 4, 9, 16, 25]
}
并且Rust的Result和Option也是函数式编程中的Either和Maybe的实现。
// `Result` is similar to `Either`
fn divide(numerator: f64, denominator: f64) -> Result<f64, &'static str> {
if denominator == 0.0 {
Err("Cannot divide by zero")
} else {
Ok(numerator / denominator)
}
}
fn main() {
match divide(4.0, 2.0) {
Ok(result) => println!("Result is {}", result),
Err(err) => println!("Error: {}", err),
}
}
// `Option` is similar to `Maybe`
fn find<T: PartialEq>(list: &[T], item: T) -> Option<usize> {
for (i, x) in list.iter().enumerate() {
if item == *x {
return Some(i);
}
}
None
}
fn main() {
let numbers = [1, 2, 3, 4, 5];
match find(&numbers, 3) {
Some(index) => println!("Found at index {}", index),
None => println!("Not found"),
}
}
所以Rust中使用函数式编程还是很舒服的。
Go #
说到Go, 它不像Rust支持那么多的函数式编程的语法。这是因为Go的设计理念是”大道至简“, 因此Go也不会引入过多的语法糖。
但是作为一个在上层开发的程序员,可以进行更深层次的抽象来满足部门函数式编程的需求。
比如有人就按照Haskell的语法封装了一套函数: lambda-go
package main
import (
"fmt"
"github.com/araujo88/lambda-go/pkg/predicate"
)
func main() {
slice := []int{1, 2, 3, 4, 5}
filtered := predicate.Filter(slice, func(x int) bool { return x > 3 })
fmt.Println(filtered)
}
在1.18版本,Go引入了泛型,这使得这种封装更加容易。
在1.23版本,Go也引入了迭代器。